project
AI-Generated Image Detection: CNN vs. LLM
A research-focused project comparing two AI approaches for detecting AI-generated images: CNN and LLM (LLaVA 1.5–7B). The goal was to evaluate which architecture performs better in pure image classification tasks.
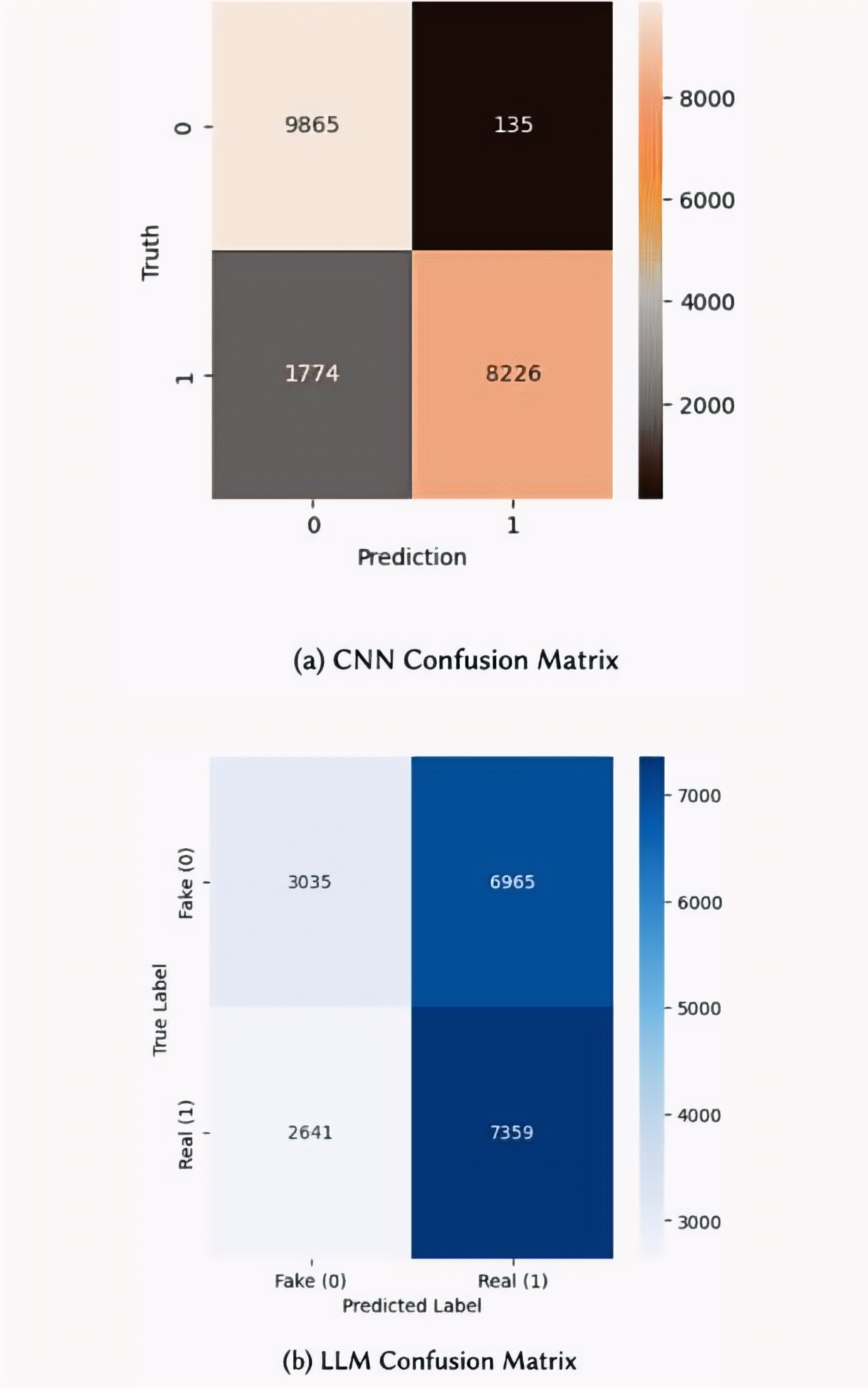
Both models were tested on the CIFAKE dataset (100k training / 20k testing images) and evaluated using precision, recall, F1-score, and confusion matrices.
The most technically challenging part was implementing and evaluating both CNN and LLM pipelines. This involved designing and training a convolutional architecture, integrating a multimodal LLM for image classification, and conducting structured performance analysis.
Result: The CNN significantly outperformed the LLM (~90% overall performance vs. ~50% precision), demonstrating that specialized vision models remain more reliable than general-purpose multimodal models for image authenticity detection.
 1 / 2
1 / 2